宏观了解 🔗
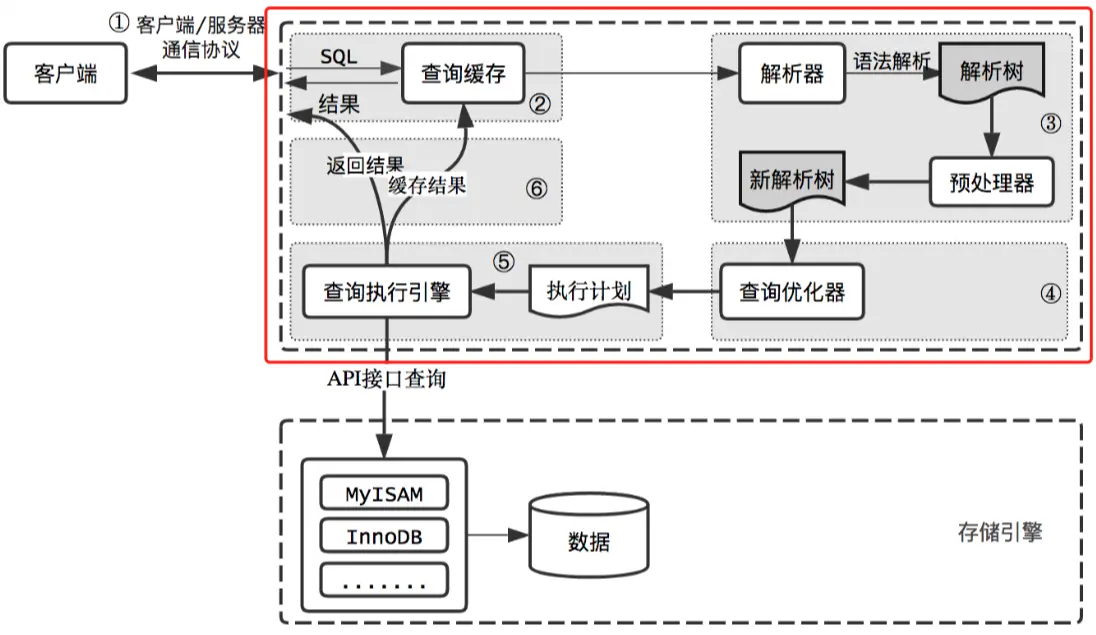
查询缓存 🔗
我们先通过show variables like '%query_cache%'来看一下默认的数据库配置,query_cache_type=ON
- 原理:MYSQL的查询缓存实质上是缓存SQL的hash值和该SQL的查询结果,如果运行相同的SQL,服务器直接从缓存中去掉结果,而不再去解析,优化,寻找最低成本的执行计划等一系列操作,大大提升了查询速度。
- 弊端:执行的SQL语句必须一样(大小写,间隔等),如果不一样将会产生不同的hash值
- 场景:通过观察云厂商,大部分情况下都是关闭查询缓存
引擎 🔗
MyISAM存储引擎 🔗
MyISAM基于ISAM存储引擎,并对其进行扩展。使用MyISAM引擎创建数据库,将产生3个文件,文件的名字以表名字开始,扩展名之处文件类型:frm文件存储表定义、数据文件的扩展名为.MYD(MYData)、索引文件的扩展名时.MYI(MYIndex)。MyISAM拥有较高的插入、查询速度,但不支持事物。MyISAM主要特性有:
- 大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
- 当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
- 每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
- 最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
- BLOB和TEXT列可以被索引
- NULL被允许在索引的列中,这个值占每个键的0~1个字节
- 所有数字键值以高字节优先被存储以允许一个更高的索引压缩
- 每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
- 可以把数据文件和索引文件放在不同目录
- 每个字符列可以有不同的字符集
- 有VARCHAR的表可以固定或动态记录长度
- VARCHAR和CHAR列可以多达64KB
InnoDB存储引擎 🔗
InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件 InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。InnoDB主要特性有:
- InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
- InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
- InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
- InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
MySQL中myisam与innodb的区别 🔗
- InnoDB支持事物,而MyISAM不支持事物
- InnoDB支持行级锁,而MyISAM支持表级锁
- InnoDB支持MVCC, 而MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB不支持全文索引,而MyISAM支持(5.6版本已经支持了)
- MYSQL引擎的文件包含(.frm-表结构文件、.myd-表数据文件,.myi-表索引文件)
- InnoDB引擎包含文件(*.frm-表结构文件,ibd-数据和索引文件)
索引 🔗
聚集索引 🔗
InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):
非聚集索引 🔗
MyISAM的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index)。
联合索引 🔗
多个字段上建立的索引,能够加速复核查询条件的检索。所以该索引也有最左匹配原则,5.6版本延伸出来的索引下推见下文
举个说明,不妨设有表:t(id PK, name KEY, sex, flag); 画外音:id是聚集索引,name是普通索引。
mysql的索引方法btree和hash的区别 🔗
- hash
- memory引擎才显示的支持Hash索引,innoDb默认是B+树
- Hash 索引仅仅能满足"=",“IN"和”<= & >=“查询,不能使用范围查询。
- Hash 索引无法被用来避免数据的排序操作。
- Hash 索引不能利用部分索引键查询。
- Hash 索引在任何时候都不能避免表扫描。
- Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
- btree 与hash的缺点就是btree的特点
哈希(hash)比树(tree)更快,索引结构为什么要设计成树型? 🔗
-
加速查找速度的数据结构,常见的有两类:
- 哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);
- 树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n));
可以看到,不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些,那为什么,索引结构要设计成树型呢?
-
索引设计成树形,和SQL的需求相关。 对于这样一个单行查询的SQL需求:
select * from t where name=”shenjian”;确实是哈希索引更快,因为每次都只查询一条记录。
画外音:所以,如果业务需求都是单行访问,例如passport,确实可以使用哈希索引 但是对于排序查询的SQL需求分组:group by 排序:order by 比较:<、>哈希型的索引,时间复杂度会退化为O(n),而树型的“有序”特性,依然能够保持O(log(n)) 的高效率。
数据库索引为什么使用B+树? 🔗
- B+树了解
- 二叉搜索树
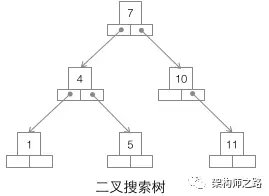 二叉搜索树,如上图,是最为大家所熟知的一种数据结构,就不展开介绍了,它为什么不适合用作数据库索引?
二叉搜索树,如上图,是最为大家所熟知的一种数据结构,就不展开介绍了,它为什么不适合用作数据库索引?
(1)当数据量大的时候,树的高度会比较高,数据量大的时候,查询会比较慢;
(2)每个节点只存储一个记录,可能导致一次查询有很多次磁盘IO; - B树
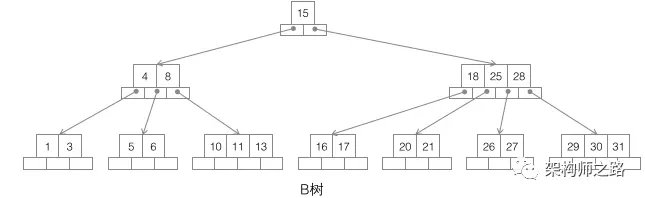 B树,如上图,它的特点是:
B树,如上图,它的特点是:
(1)不再是二叉搜索,而是m叉搜索;
(2)叶子节点,非叶子节点,都存储数据;
(3)中序遍历,可以获得所有节点;
树被作为实现索引的数据结构被创造出来,是因为它能够完美的利用“局部性原理”。
什么是回表查询? 🔗
- InnoDB聚集索引和普通索引有什么差异? InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
- 如果表定义了PK,则PK就是聚集索引;
- 如果表没有定义PK,则第一个not NULL unique列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引; 所以PK查询非常快,直接定位行记录。
-
InnoDB普通索引的叶子节点存储主键值。 注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
-
回表查询过程 举个栗子,不妨设有表:t(id PK, name KEY, sex, flag); 表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
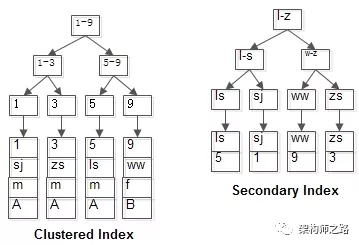
两个B+树索引分别如上图: (1)id为PK,聚集索引,叶子节点存储行记录; (2)name为KEY,普通索引,叶子节点存储PK值,即id; 既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢? 通常情况下,需要扫码两遍索引树。 例如:
select * from t where name='lisi';

如红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是回表查询
索引覆盖(Covering index)? 🔗
- 什么是索引覆盖
- MySQL官网,类似的说法出现在explain查询计划优化章节,即
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。 - 不管是SQL-Server官网,还是MySQL官网,都表达了:
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
- 如何实现索引覆盖?
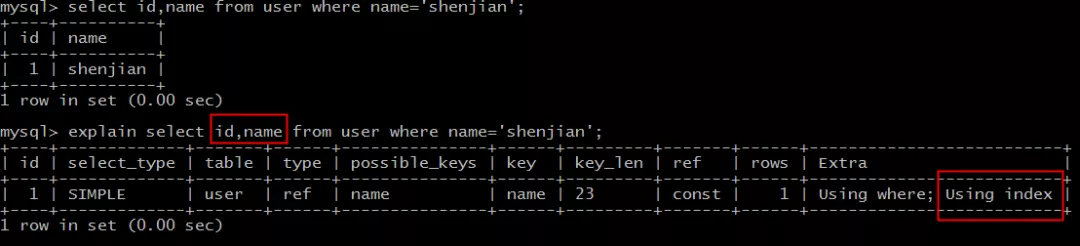 能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
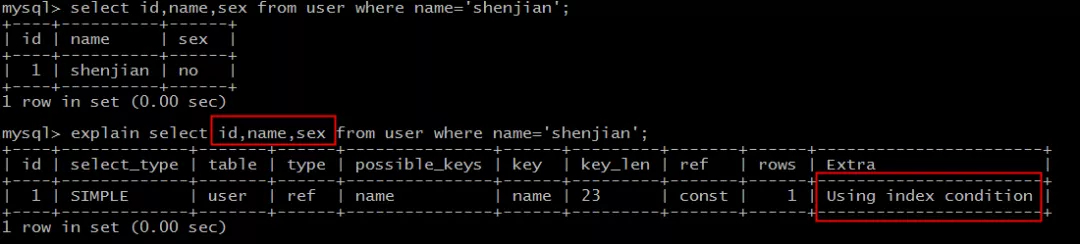 能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
如果把(name)单列索引升级为
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
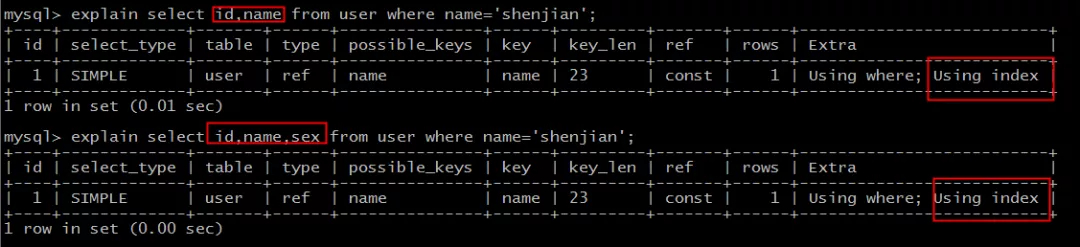
都能够命中索引覆盖,无需回表。
3. 哪些场景可以利用索引覆盖来优化SQL?
- 全表count查询优化
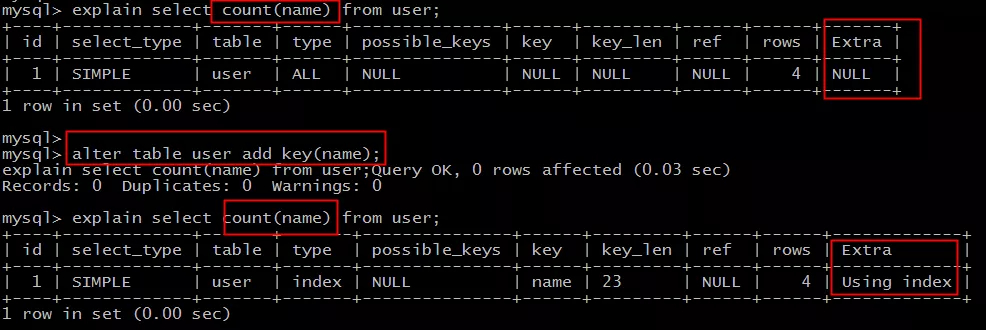
- 列查询回表优化(同上面的例子)
非常隐蔽的全表扫描,不能命中索引 🔗
列类型与where 值类型不符合不能命中索引,会导致全表扫描- 相
join的两个表的字符编码不同,不能命中索引,会导致迪卡尔积的运算
数据库主键索引不宜太长??(特指InnoDB) 🔗
- MyISAM引擎,无影响。原因:进行检索时,会先从索引树定位到记录指针,再通过指针定位到具体的记录
- InnoDB通过主键索引查询时,能够直接定位到行记录。 原因:身份证号id_code是一个比较长的字符串,每个索引都存储这个值,在数据量大,内存珍贵的情况下,MySQL有限的缓冲区,存储的索引与数据会减少,磁盘IO的概率会增加。同时,索引占用的磁盘空间也会增加。
- 总结 (1)MyISAM的索引与数据分开存储,索引叶子存储指针,主键索引与普通索引无太大区别; (2)InnoDB的聚集索引和数据行统一存储,聚集索引存储数据行本身,普通索引存储主键; (3)InnoDB不建议使用太长字段作为PK(此时可以加入一个自增键PK),MyISAM则无所谓;
like查询一定不命中索引吗? 🔗
mysql在使用like查询,%在最前面不会用到索引,中间或最后是会用到索引的,只是越靠前扫描的行数越多

索引下推 🔗
例如对于user_table表,我们现在有(username,age)联合索引,如果现在有一个需求,查出名称中以“张”开头且年龄小于等于10的用户信息,语句如下:“select * from user_table where username like ‘张%’ and age > 10”.
- 索引下推:like ‘zhang%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
- 注意:
- innodb引擎的表,索引下推只能用于二级索引。 原因:innodb的主键索引树叶子结点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
- 索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。
假设表t有联合索引(a,b),下面语句可以使用索引下推提高效率
select * from t where a > 2 and b > 10;
日志 🔗
MySQL多少种日志 🔗
- 错误日志:记录mysql启动和运行的出错信息,也记录一些警告信息或者正确的信息,在my.cnf中log_error指定路径。
- 查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
- 慢查询日志:设置一个阈值(log_query_time),将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
- 二进制日志:又叫做bin-log日志,纪录所有的写操作(增改删),纪录一些执行时间,执行时长,数据变更等。主要用于
恢复、复制、审计,生成的文件格式mysql-bin.001..等一系列序号。 - 中继日志:理解上relay log很多方面都跟binary log差不多。区别是:从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致
- 事务日志: 事务日志文件名为
ib_logfile0和ib_logfile1,默认存放在表空间所在目录
MySQL binlog的几种日志录入格式以及区别 🔗
- 格式:
Statement,Row,Mixedlevel - 区别:
- 基于语句纪录(Statement ):每一条会修改数据的sql都会记录在binlog中
- 优点:只需要记录执行语句的细节和上下文环境,避免了记录每一行的变化,在一些修改记录较多的情况下相比ROW level能大大减少binlog日志量,节约IO,提高性能;还可以用于实时的还原;
- 缺点:为了保证sql语句能在slave上正确执行,必须记录上下文信息,以保证所有语句能在slave得到和在master端执行时候相同的结果;另外,主从复制时,存在部分函数(如sleep)及存储过程在slave上会出现与master结果不一致的情况,而相比Row level记录每一行的变化细节,绝不会发生这种不一致的情况.
- 基于行(Row):仅保存记录被修改细节,不记录sql语句上下文相关信息。
- 优点: 能非常清晰的记录下每行数据的修改细节,不需要记录上下文相关信息,因此不会发生某些特定情况下的procedure、function、及trigger的调用触发无法被正确复制的问题,任何情况都可以被复制,且能加快从库重放日志的效率,保证从库数据的一致性
- 缺点:由于所有的执行的语句在日志中都将以每行记录的修改细节来记录,因此,可能会产生大量的日志内容,干扰内容也较多;比如一条update语句,如修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中,实际等于重建了表。
- 混合模式(Mixedlevel):是以上两种level的混合使用 一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则 采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择 一种.新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的 变更。
...............................................................................
# at 552
#131128 17:50:46 server id 1 end_log_pos 665 Query thread_id=11 exec_time=0 error_code=0 +++->执行时间:17:50:46;pos点:665
SET TIMESTAMP=1385632246/*!*/;
update zyyshop.stu set name='李四' where id=4 +++->执行的SQL
/*!*/;
# at 665
#131128 17:50:46 server id 1 end_log_pos 692 Xid = 1454 +++->执行时间:17:50:46;pos点:692
...............................................................................
事物 🔗
数据库事务特性(ACID) 🔗
- 原子性:即步骤要么都成功,要么都失败
- 一致性:即操作的总数据量状态保证一致。例如A->B转账总数木变化是100,不多也不少
- 隔离性:即每个事物的操作,不影响其他的事物
- 持久性:即一旦提交结果永久保存
事物是如何通过日志实现的 🔗
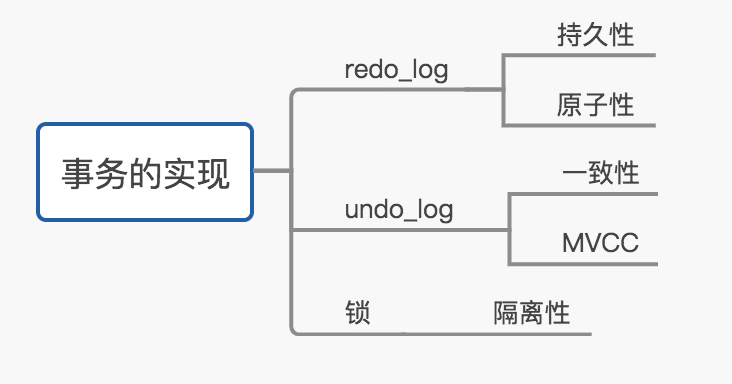
redo_log 实现持久化和原子性,而undo_log实现一致性,二种日志均可以视为一种恢复操作,redo_log是恢复提交事务修改的页操作,而undo_log是回滚行记录到特定版本。二者记录的内容也不同,redo_log是物理日志,记录页的物理修改操作,而undo_log是逻辑日志,根据每行记录进行记录。
- 事务日志是通过redo(重做日志)和innodb的存储引擎日志缓冲(Innodb log buffer)来实现的,
- 当开始一个事务的时候,会记录该事务的lsn(log sequence number)号;
- 当事务执行时,会往InnoDB存储引擎的日志的日志缓存里面插入事务日志;
- 当事务提交时,必须将存储引擎的日志缓冲写入磁盘(通过innodb_flush_log_at_trx_commit来控制),也就是写数据前,需要先写日志。这种方式称为“预写日志方式”
事务干扰例子 🔗
- 读脏
- 事务A,先执行,处于未提交的状态:insert into t values(4, wangwu);
- 事务B,后执行,也未提交:select * from t;
如果事务B能够读取到(4, wangwu)这条记录,事务A就对事务B产生了影响,
这个影响叫做“读脏”,读到了未提交事务操作的记录。
- 不可重复读
- 事务A,先执行:select * from t where id=1;结果集为:1, zhangsan
- 事务B,后执行,并且提交:update t set name=xxoo where id=1;commit;
- 事务A,再次执行相同的查询:select * from t where id=1;结果集为:1, xxoo
这次是已提交事务B对事务A产生的影响,
这个影响叫做“不可重复读”,一个事务内相同的查询,得到了不同的结果。
- 幻读
- 事务A,先执行:select * from t where id>3; 结果为null
- 事务B,后执行,并且提交:insert into t values(4, wangwu);commit;
- 事务A,首次查询了id>3的结果为NULL,于是想插入一条为4的记录:insert into t values(4, xxoo);结果集为:Error : duplicate key!
这次是已提交事务B对事务A产生的影响,这个影响叫做“幻读”。
数据库的隔离级别 🔗
- 未提交读(Read Uncommitted)(S锁): 此时,可能读取到不一致的数据,即“读脏”。这是并发最高,一致性最差的隔离级别。高并发量的场景下,几乎不会使用
- 串行化(Serializable)(X锁): 这种事务的隔离级别下,所有select语句都会被隐式的转化为select … in share mode.这可能导致,如果有未提交的事务正在修改某些行,所有读取这些行的select都会被阻塞住。这是一致性最好的,但并发性最差的隔离级别。可以解决 脏读 不可重复读 和 虚读+++相当于锁表,所以高并发量的场景下,几乎不会使用
- 可重复读(Repeated Read, RR)(X锁),这是InnoDB默认的隔离级别
(1)
普通的select使用快照读(snapshot read),这是一种不加锁的一致性读(Consistent Nonlocking Read),底层使用MVCC来实现 (2)加锁的select(select … in share mode / select … for update), update, delete等语句,它们的锁,依赖于它们是否在唯一索引(unique index)上使用了唯一的查询条件(unique search condition),或者范围查询条件(range-type search condition):- 在唯一索引上使用唯一的查询条件,会使用记录锁(record lock),而不会封锁记录之间的间隔,即不会使用间隙锁(gap lock)与临键锁(next-key lock)
- 范围查询条件,会使用间隙锁与临键锁,锁住索引记录之间的范围,避免范围间插入记录,以避免产生幻影行记录,以及避免不可重复的读
- 读已提交(Read Committed, RC): 这是互联网最常用的隔离级别
- 普通读是快照读;
- 加锁的select, update, delete等语句,除了在外键约束检查(foreign-key constraint checking)以及重复键检查(duplicate-key checking)时会封锁区间,其他时刻都只使用记录锁;
- 此时,其他事务的插入依然可以执行,就可能导致,读取到幻影记录。
MVCC解释 🔗
- MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
- 核心原理
(1) 写任务发生时,将数据克隆一份,以版本号区分;
(2) 写任务操作新克隆的数据,直至提交;
(3) 并发读任务可以继续读取旧版本的数据,不至于阻塞;
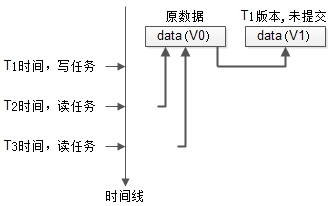 如上图:
如上图: - 最开始数据的版本是V0;
- T1时刻发起了一个写任务,这是把数据clone了一份,进行修改,版本变为V1,但任务还未完成;
- T2时刻并发了一个读任务,依然可以读V0版本的数据;
- T3时刻又并发了一个读任务,依然不会阻塞; 可以看到,数据多版本,通过“读取旧版本数据”能够极大提高任务的并发度。 提高并发的演进思路,就在如此:
- 普通锁,本质是串行执行
- 读写锁,可以实现读读并发
- 数据多版本,可以实现读写并发
锁 🔗
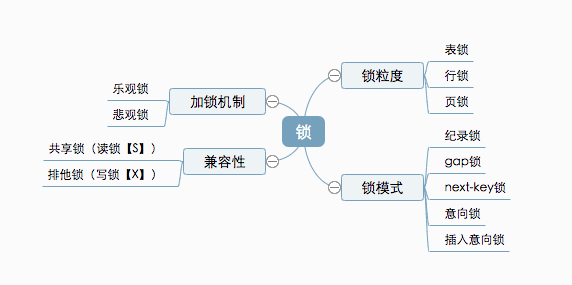
锁机制 🔗
- 悲观锁:利用了数据库内部提供的锁机制;在并发过程中一旦有一个事务持有了数据库记录的锁,其他线程就不能再对数据库进行更新
- 乐观锁:乐观锁是一种不会阻塞其它线程并发的机制,它不会使用数据库的锁进行实现。所以就不会引起线程的频繁挂起和恢复,这样效率就提高了。它的实现关键在于CAS算法或者版本号机制。
- 版本号机制:
- 先读task表的数据(实际上这个表只有一条记录),得到version的值为versionValue
- update task set value = newValue,version = versionValue + 1 where version = versionValue;
- CAS算法:
- 版本号机制:
锁粒度 🔗
- 行锁详解
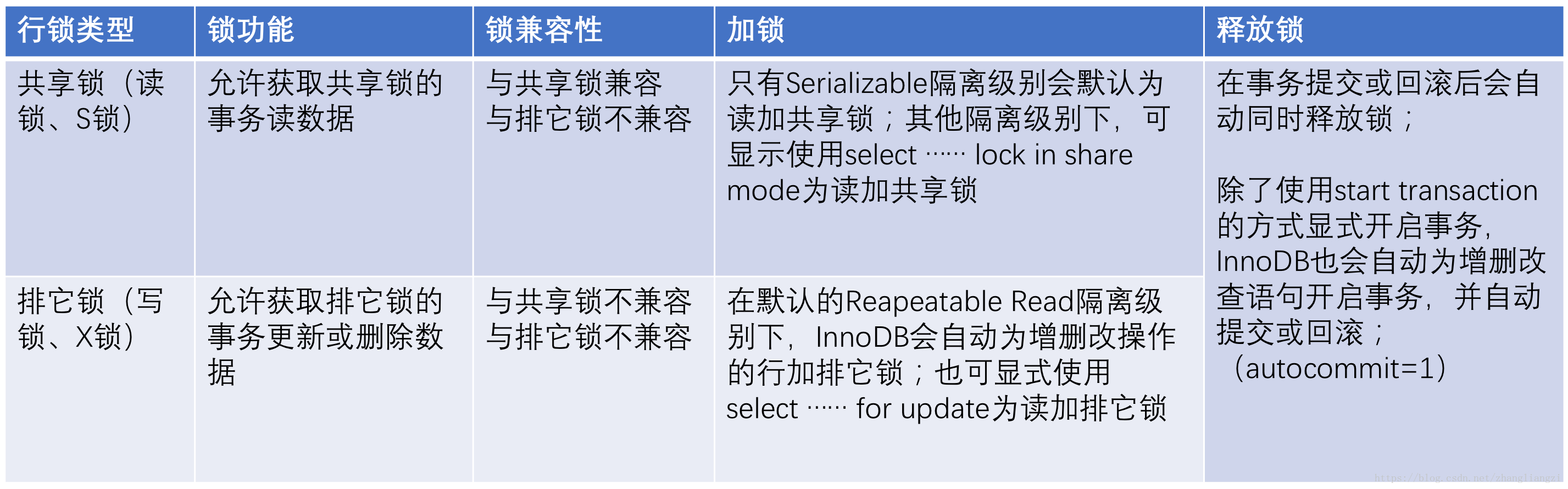
- 表锁详解
- 页锁详解
当前读与快照读 🔗
- 当前读 使用当前读的操作主要包括:显式加锁的读操作与插入/更新/删除等写操作,如下所示:
select * from table where ? lock in share mode;
select * from table where ? for update;
insert into table values (…);
update table set ? where ?;
delete from table where ?;
- 快照读 即不加锁读,读取记录的快照版本而非最新版本,通过MVCC实现;
锁模式 🔗
| 锁模式 | 锁定内容 |
|---|---|
| Record Lock | 记录锁,锁定一条纪录 |
| Gap Lock | 间隙锁,锁定一个区间 |
| Next-key Lock | 记录+间隙锁,锁定一个区间+记录行 |
网络 🔗
主从复制原理 🔗
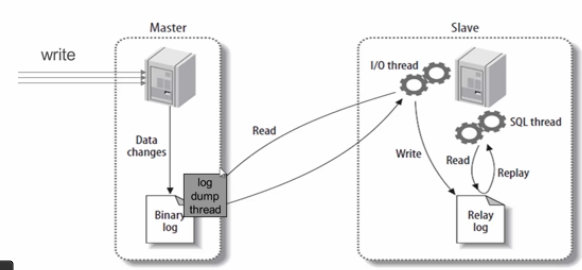
- mysql启动以后会存在2个进程,一个是sqlThred进程一个IOThred进程
- 在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制
- Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置之后开始发送binlog日志内容
- Master服务器接收到来自Slave服务器的IO线程的请求后,二进制转储IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在master服务器端记录的新的binlog文件名称,以及在新的binlog中的下一个指定更新位置。
- 当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(MySQL-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
- Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点
主从延迟的问题和解决办法 🔗
- 主从同步的延迟的原因:我们知道,一个服务器开放N个链接给客户端来连接的, 这样有会有大并发的更新操作, 但是从服务器的里面读取binlog 的线程仅有一个, 当某个SQL在从服务器上执行的时间稍长 或者由于某个SQL要进行锁表就会导致,主服务器的SQL大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
- 解决办法: 1)实际上主从同步延迟根本没有什么一招制敌的办法,因为所有的SQL必须都要在从服务器里面执行一遍,但是主服务器如果不断的有更新操作源源不断的写入,那么一旦有延迟产生,那么延迟加重的可能性就会原来越大。当然我们可以做一些缓解的措施。 2)我们知道因为主服务器要负责更新操作,他对安全性的要求比从服务器高,所有有些设置可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit=1之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog,innodb_flush_log_at_trx_commit也可以设置为0来提高sql的执行效率这个能很大程度上提高效率。另外就是使用比主库更好的硬件设备作为slave。 3)就是把,一台从服务器当度作为备份使用,而不提供查询,那边他的负载下来了,执行relaylog里面的SQL效率自然就高了。 4)增加从服务器喽,这个目的还是分散读的压力,从而降低服务器负载。
压力测试 🔗
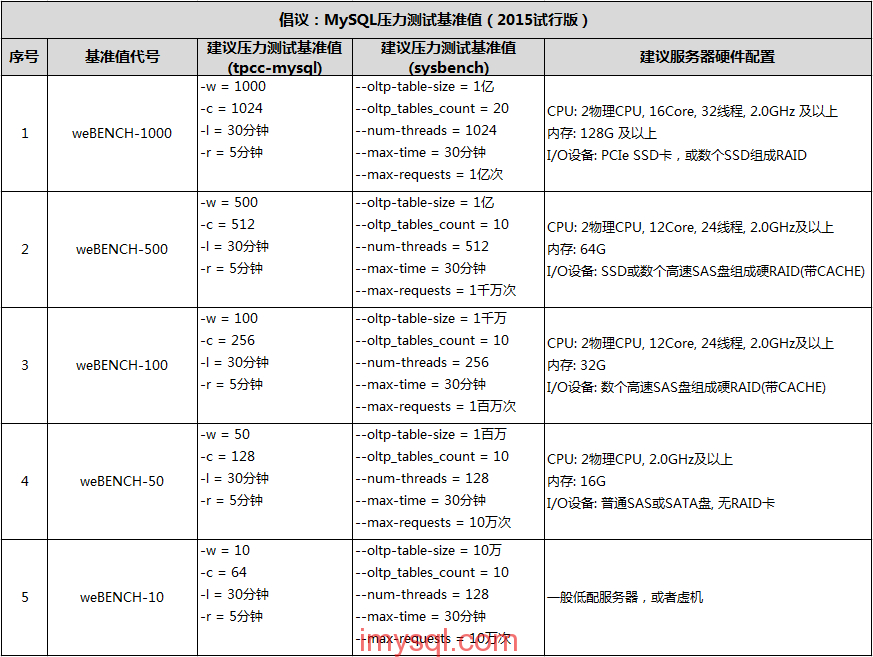
https://imysql.com/tag/%E5%8E%8B%E6%B5%8B 比较常用的MySQL基准压力测试工具有 tpcc-mysql、sysbench、mysqlslap 等几个。
延伸知识点 🔗
MYSQL count总结 🔗
-
COUNT有几种用法?count(*),count(常数),count(列名)
-
COUNT(字段名)和COUNT()的查询结果有什么不同?为什么《阿里巴巴Java开发手册》建议使用COUNT() count()是SQL92定义的标准语法,count()会统计值为null的行,count(列明)不会统计改列为null的行
-
COUNT(1)和COUNT()、count(列名)之间有什么不同? COUNT(常量) 和 COUNT()表示的是直接查询符合条件的数据库表的行数。而COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。 除了查询得到结果集有区别之外,COUNT()相比COUNT(常量) 和 COUNT(列名)来讲,COUNT()是SQL92定义的标准统计行数的语法,因为他是标准语法,所以MySQL数据库对他进行过很多优化。
-
COUNT(1)和COUNT(*)之间的效率哪个更高?
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
画重点:same way , no performance difference。所以,对于COUNT(1)和COUNT(*),MySQL的优化是完全一样的,根本不存在谁比谁快! 建议使用COUNT(*)!因为这个是SQL92定义的标准统计行数的语法,而且本文只是基于MySQL做了分析,关于Oracle中的这个问题,也是众说纷纭的呢。
-
MySQL的MyISAM引擎对COUNT()做了哪些优化? 因为MyISAM的锁是表级锁,所以同一张表上面的操作需要串行进行,所以,MyISAM做了一个简单的优化,那就是它可以把表的总行数单独记录下来,如果从一张表中使用COUNT()进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有where条件。
-
MySQL的InnoDB引擎对COUNT()做了哪些优化? 在InnoDB中,使用COUNT()查询行数的时候,不可避免的要进行扫表了,那么,就可以在扫表过程中下功夫来优化效率了。 从MySQL 8.0.13开始,针对InnoDB的SELECT COUNT() FROM tbl_name语句,确实在扫表的过程中做了一些优化。前提是查询语句中不包含WHERE或GROUP BY等条件。 我们知道,COUNT()的目的只是为了统计总行数,所以,他根本不关心自己查到的具体值,所以,他如果能够在扫表的过程中,选择一个成本较低的索引进行的话,那就可以大大节省时间。 我们知道,InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。 所以,相比之下,非聚簇索引要比聚簇索引小很多,所以MySQL会优先选择最小的非聚簇索引来扫表。所以,当我们建表的时候,除了主键索引以外,创建一个非主键索引还是有必要的。 至此,我们介绍完了MySQL数据库对于COUNT(*)的优化,这些优化的前提都是查询语句中不包含WHERE以及GROUP BY条件。
-
上面提到的MySQL对COUNT(*)做的优化,有一个关键的前提是什么? 无where条件或者group by等条件
什么是局部性原理? 🔗
局部性原理的逻辑是这样的:
- 内存读写块,磁盘读写慢,而且慢很多;
- 磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘IO,提高效率;(通常,一页数据是4K)
- 局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO;
B树为何适合做索引? 🔗
- 由于是m分叉的,高度能够大大降低;
- 每个节点可以存储j个记录,如果将节点大小设置为页大小,例如4K,能够充分的利用预读的特性,极大减少磁盘IO;
B+树 🔗
 B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。下面是往B树中依次插入
B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。下面是往B树中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
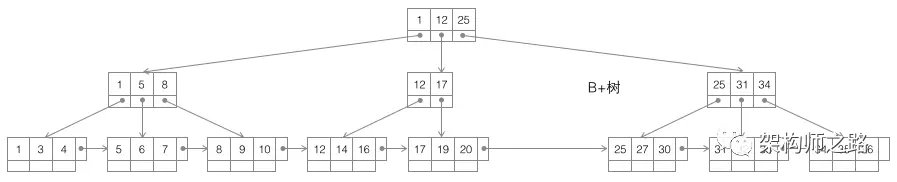
 B+树,如上图,仍是m叉搜索树,在B树的基础上,做了一些改进:
B+树,如上图,仍是m叉搜索树,在B树的基础上,做了一些改进:
- 非叶子节点不再存储数据,数据只存储在同一层的叶子节点上;(画外音:B+树中根到每一个节点的路径长度一样,而B树不是这样。)
- 叶子之间,增加了链表,获取所有节点,不再需要中序遍历; 这些改进让B+树比B树有更优的特性:
- 范围查找,定位min与max之后,中间叶子节点,就是结果集,不用中序回溯;(画外音:范围查询在SQL中用得很多,这是B+树比B树最大的优势。)
- 叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储;
- 非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引; 最后,量化说下,为什么m叉的B+树比二叉搜索树的高度大大大大降低? 大概计算一下: (1)局部性原理,将一个节点的大小设为一页,一页4K,假设一个KEY有8字节,一个节点可以存储500个KEY,即j=500 (2)m叉树,大概m/2<= j <=m,即可以差不多是1000叉树 (3)那么: 一层树:1个节点,1500个KEY,大小4K 二层树:1000个节点,1000500=50W个KEY,大小10004K=4M 三层树:10001000个节点,10001000500=5亿个KEY,大小100010004K=4G 可以看到,存储大量的数据(5亿),并不需要太高树的深度(高度3),索引也不是太占内存(4G)。