基本概念 🔗
Redis性能如此高的原因,我总结了如下几点:
- 纯内存操作
- 单线程
- 高效的数据结构
- 合理的数据编码
- 其他方面的优化
在 Redis 中,常用的几种数据结构和应用场景如下:
- String:缓存、计数器、分布式锁等。
- List:链表、队列、微博关注人时间轴列表等。
- Hash:用户信息、Hash 表等。
- Set:去重、赞、踩、共同好友等。
- Zset:访问量排行榜、点击量排行榜等。
- HyperLogLog: 网站UV,独立IP计算等,主要也是一些去重计算,对数据精度要求不高,主要由于计算数据空间是固定的
- Geo:GEO(地理位置)的支持,主要是对经纬度一个位置计算等特性
内部数据结构 🔗
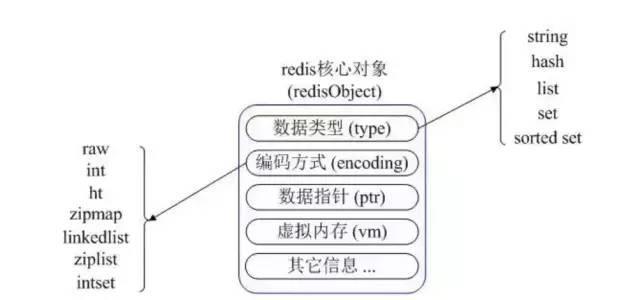
redis的底层数据结构有以下7种,包括简单动态字符串(SDS),链表、字典、跳跃表、整数集合、压缩列表、对象。
简单动态字符串(SDS) 🔗
Redis 是用 C 语言开发完成的,但在 Redis 字符串中,并没有使用 C 语言中的字符串,而是用一种称为 SDS(Simple Dynamic String)的结构体来保存字符串。 在redis数据库里,包含字符串值的键值对在底层都是由SDS实现的。除了用来保存数据库中的字符串值之外,sds还被用来作缓冲区(buffer):AOF(一种持久化策略)模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的。
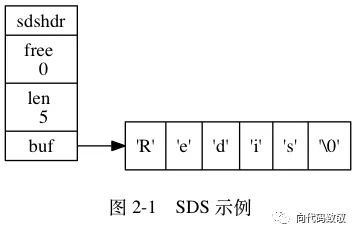
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* 记录buff数组中已使用字节的数量 */
uint64_t free; /* 记录未使用字节数量*/
char buf[]; /*存储实际内容*/
};
例如:执行命令 set key value,key 和 value 都是一个 SDS 类型的结构存储在内存中。
SDS 与 C 字符串的区别 🔗
-
常数时间内获得字符串长度: C 字符串本身不记录长度信息,每次获取长度信息都需要遍历整个字符串,复杂度为 O(n);C 字符串遍历时遇到’\0‘ 时结束。 SDS 中 len 字段保存着字符串的长度,所以总能在常数时间内获取字符串长度,复杂度是 O(1)。
-
避免缓冲区溢出 假设在内存中有两个紧挨着的两个字符串,s1=“xxxxx"和 s2=“yyyyy”
由于在内存上紧紧相连,当我们对 s1 进行扩充的时候,将 s1=“xxxxxzzzzz”后,由于没有进行相应的内存重新分配,导致 s1 把 s2 覆盖掉,导致 s2 被莫名其妙的修改。
但 SDS 的 API 对 zfc 修改时首先会检查空间是否足够,若不充足则会分配新空间,避免了缓冲区溢出问题。
减少字符串修改时带来的内存重新分配的次数 🔗
由于C语言修改字符需要重新分配空间
而SDS实现了预分配和惰性释放
预分配规则:SDS空间进行扩充时,会分配足够的内存空间还会分配额外未使用的空间。如果对 SDS 修改后,len 的长度小于 1M,那么程序将分配和 len 相同长度的未使用空间。举个例子,如果 len=10,重新分配后,buf 的实际长度会变为 10(已使用空间)+10(额外空间)+1(空字符)=21。如果对 SDS 修改后 len 长度大于 1M,那么程序将分配 1M 的未使用空间。
惰性空间释放:当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用 free 中未使用的空间,减少了内存的分配。
3.字典(Hash) 🔗
Redis底层hash结构如下:
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
}
typedef struct dictht{
//哈希表数组
dectEntrt **table;
//哈希表大小
unsigned long size;
//
unsigned long sizemask;
//哈希表已有节点数量
unsigned long used;
}
重要的两个字段是 dictht 和 trehashidx
Rehash 🔗
Rehash解释:随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。扩展和收缩哈希表的工作可以通过执行 rehash (重新散列)操作来完成
由上段代码,我们可知 dict 中存储了一个 dictht 的数组,长度为 2,表明这个数据结构中实际存储着两个哈希表 ht[0] 和 ht[1],为什么要存储两张 hash 表呢?
当然是为了Rehash,Rehash的过程
- 为 ht[1] 分配空间。如果是扩容操作,ht[1] 的大小为第一个大于等于 ht[0].used*2 的 2^n;如果是缩容操作,ht[1] 的大小为第一个大于等于 ht[0].used 的 2^n。
- 将 ht[0] 中的键值 Rehash 到 ht[1] 中。
- 当 ht[0] 全部迁移到 ht[1] 中后,释放 ht[0],将 ht[1] 置为 ht[0],并为 ht[1] 创建一张新表,为下次 Rehash 做准备。
渐进式 Rehash 🔗
上面提到的如果ht[0]全部移动到ht[1]中,如果数据量小很快,如果数据量很大则会有影响使用 所以redis采用了分多次、渐进式的迁移策略
- 为 ht[1] 分配空间,让字典同时拥有 ht[0] 和 ht[1] 两个哈希表。
- 字典中维护一个 rehashidx,并将它置为 0,表示 Rehash 开始。
- 在 Rehash 期间,每次对字典操作时,程序还顺便将 ht[0] 在 rehashidx 索引上的所有键值对 rehash 到 ht[1] 中,当 Rehash 完成后,将 rehashidx 属性+1。当全部 rehash 完成后,将 rehashidx 置为 -1,表示 rehash 完成。 注意,由于维护了两张 Hash 表,所以在 Rehash 的过程中内存会增长。另外,在 Rehash 过程中,字典会同时使用 ht[0] 和 ht[1]。
所以在删除、查找、更新时会在两张表中操作,在查询时会先在第一张表中查询,如果第一张表中没有,则会在第二张表中查询。但新增时一律会在 ht[1] 中进行,确保 ht[0] 中的数据只会减少不会增加。
4. Zset底层 🔗
zset底层的存储结构包括ziplist或skiplist,在同时满足以下两个条件的时候使用ziplist,其他时候使用skiplist,两个条件如下:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
当ziplist作为zset的底层存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
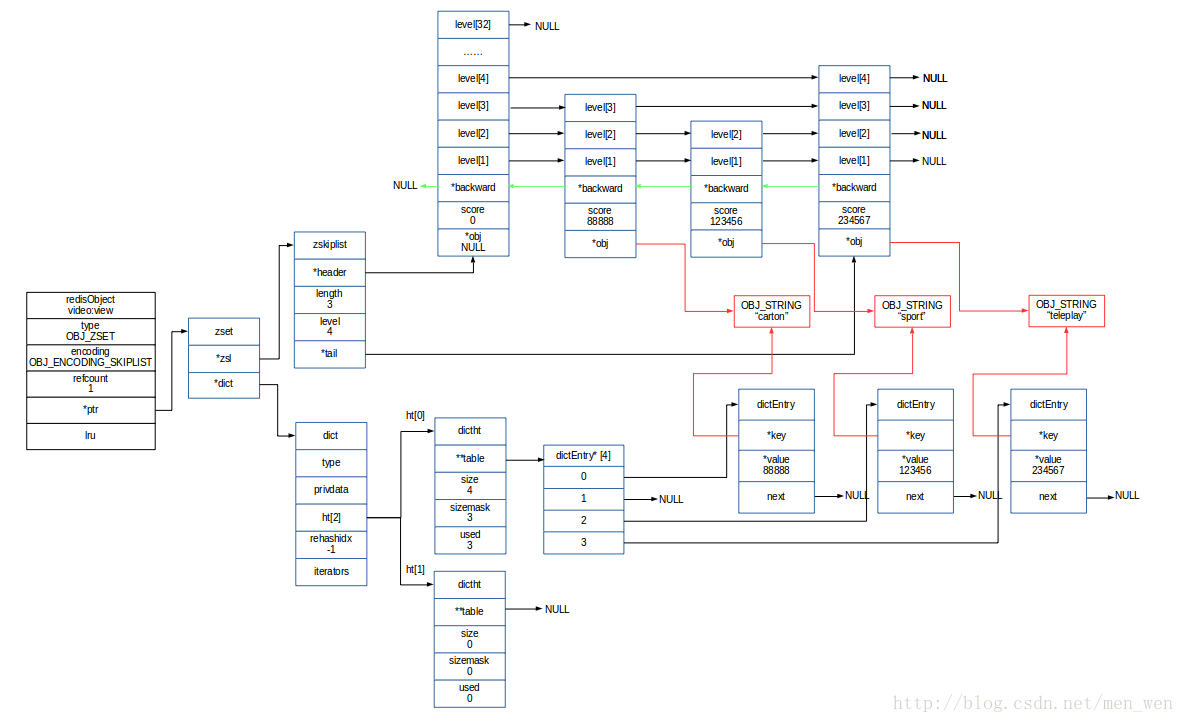
当skiplist作为zset的底层存储结构的时候,使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
ziplist数据结构

skiplist数据结构 skiplist作为zset的存储结构,整体存储结构如下图,核心点主要是包括一个dict对象和一个skiplist对象。dict保存key/value,key为元素,value为分值;skiplist保存的有序的元素列表,每个元素包括元素和分值。两种数据结构下的元素指向相同的位置。
5. Set底层 🔗
set的底层存储intset和hashtable是存在编码转换的,使用intset存储必须满足下面两个条件,否则使用hashtable,条件如下:
- 结合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过512个
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
set的单个元素的添加过程,首先如果已经是hashtable的编码,那么我们就走正常的hashtable的元素添加,如果原来是intset的情况,那么我们就需要进行如下判断:
- 如果能够转成int的对象(isObjectRepresentableAsLongLong),那么就用intset保存。
- 如果用intset保存的时候,如果长度超过512(REDIS_SET_MAX_INTSET_ENTRIES)就转为hashtable编码。
List底层 🔗
redis list数据结构底层采用压缩列表ziplist或linkedlist两种数据结构进行存储,首先以ziplist进行存储,在不满足ziplist的存储要求后转换为linkedlist列表。 当列表对象同时满足以下两个条件时,列表对象使用ziplist进行存储,否则用linkedlist存储。
- 列表对象保存的所有字符串元素的长度小于64字节
- 列表对象保存的元素数量小于512个。
编码转化 🔗
Redis 使用对象(redisObject)来表示数据库中的键值,当我们在 Redis 中创建一个键值对时,至少创建两个对象,一个对象是用做键值对的键对象,另一个是键值对的值对象。
例如我们执行 SET MSG XXX 时,键值对的键是一个包含了字符串“MSG“的对象,键值对的值对象是包含字符串”XXX”的对象。
redisObject 的结构如下:
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//...
}robj;
其中 type 字段记录了对象的类型,包含字符串对象、列表对象、哈希对象、集合对象、有序集合对象。
ptr 指针字段指向对象底层实现的数据结构,而这些数据结构是由 encoding 字段决定的,每种对象至少有两种数据编码:
 可以通过 object encoding key 来查看对象所使用
可以通过 object encoding key 来查看对象所使用
String 对象的编码转化 🔗
String 对象的编码可以是 int 或 raw,对于 String 类型的键值,如果我们存储的是纯数字,Redis 底层采用的是 int 类型的编码,如果其中包括非数字,则会立即转为 raw 编码:
127.0.0.1:6379> set str 1
OK
127.0.0.1:6379> object encoding str
"int"
127.0.0.1:6379> set str 1a
OK
127.0.0.1:6379> object encoding str
"raw"
127.0.0.1:6379>
List 对象的编码转化 🔗
List 对象的编码可以是ziplist 或 linkedlist,对于 List 类型的键值,当列表对象同时满足以下两个条件时,采用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于 64 字节。
- 列表对象保存的元素个数小于 512 个。 如果不满足这两个条件的任意一个,就会转化为 linkedlist 编码。注意:这两个条件是可以修改的,在 redis.conf 中:
list-max-ziplist-entries 512
list-max-ziplist-value 64
Set 类型的编码转化 🔗
Set 对象的编码可以是 intset 或 hashtable,intset 编码的结构对象使用整数集合作为底层实现,把所有元素都保存在一个整数集合里面。
127.0.0.1:6379> sadd set 1 2 3
(integer) 3
127.0.0.1:6379> object encoding set
"intset"
127.0.0.1:6379>
如果 set 集合中保存了非整数类型的数据时,Redis 会将 intset 转化为 hashtable:
127.0.0.1:6379> sadd set 1 2 3
(integer) 3
127.0.0.1:6379> object encoding set
"intset"
127.0.0.1:6379> sadd set a
(integer) 1
127.0.0.1:6379> object encoding set
"hashtable"
127.0.0.1:6379>
当 Set 对象同时满足以下两个条件时,对象采用 intset 编码:
- 保存的所有元素都是整数值(小数不行)。
- Set 对象保存的所有元素个数小于 512 个。 不能满足这两个条件的任意一个,Set 都会采用 hashtable 存储。注意:第两个条件是可以修改的,在 redis.conf 中:
set-max-intset-entries 512
Hash 对象的编码转化 🔗
Hash 对象的编码可以是 ziplist 或 hashtable,当 Hash 以 ziplist 编码存储的时候,保存同一键值对的两个节点总是紧挨在一起,键节点在前,值节点在后: 当 Hash 对象同时满足以下两个条件时,Hash 对象采用 ziplist 编码:
- Hash 对象保存的所有键值对的键和值的字符串长度均小于 64 字节。
- Hash 对象保存的键值对数量小于 512 个。 如果不满足以上条件的任意一个,ziplist 就会转化为 hashtable 编码。注意:这两个条件是可以修改的,在 redis.conf 中:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
Zset 对象的编码转化 🔗
Zset 对象的编码可以是 ziplist 或 zkiplist,当采用 ziplist 编码存储时,每个集合元素使用两个紧挨在一起的压缩列表来存储。
第一个节点存储元素的成员,第二个节点存储元素的分值,并且按分值大小从小到大有序排列。
当 Zset 对象同时满足一下两个条件时,采用 ziplist 编码:
- Zset 保存的元素个数小于 128。
- Zset 元素的成员长度都小于 64 字节。 如果不满足以上条件的任意一个,ziplist 就会转化为 zkiplist 编码。注意:这两个条件是可以修改的,在 redis.conf 中:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64